[网络爬虫]什么是"爬虫陷阱"以及常见的爬虫难点汇总分析
·
文章编辑:孔宇SEO
·
所属栏目:基础教程
一、什么是爬虫陷阱:
“蜘蛛陷阱”是阻止蜘蛛程序爬行网站的障碍物,一些网站设计技术对搜索引擎说很不友好,不利于蜘蛛爬行和抓取,这些技术被称为蜘蛛陷阱。 最大的特点是当蜘蛛抓取某个特定URL的时候,它便进入了无限循环,只有入口,没有出口。

二、常见的“蜘蛛陷阱”有哪些:
1、站内搜索
这是一个常见且容易造成“蜘蛛陷阱”的地方,当你试图在站内搜索某些特定关键词的时候,如果类似search.php?q=这样的URL地址被搜索引擎抓取与收录,那么很可能产生大量无意义的搜索结果页面。
解决方法:你可以通过Robots.txt这个文件,屏蔽动态参数。
2、电商产品
如果你以往有过操作电商网站的经历,那么你会遇到产品SKU的多样性的问题,同一个主题内容,会根据SKU的不同,产生多个URL,造成大量的内容重复页面,这也导致严重浪费蜘蛛抓取频率。还有一种特殊的“蜘蛛陷阱”与电商产品页面类似,就是动态的内容插入,这也往往导致蜘蛛陷入温柔的陷阱。
解决方法:确保URL的规范性,你可以试图利用rel=canonical这个标签来解决类似问题。
3、Flash网站
为了满足用户的视觉体验,建站公司通常会使用Flash网站,给用户搭建企业官网,这样看起来非常美观,但由于目前搜索引擎并不能很好的抓取与识别flash内容,往往导致站点排名很难提升。
解决方法:不要做整站flash,尽量将flash嵌入网页内容的一部分。
4、限制性内容
对于一些站点,出去吸引粉丝的目的,很多内容只有登录才能查看,特别是一些强制cookie的操作,这诱导与欺骗了蜘蛛,它很难识别内容,并且不断的尝试抓取这个URL。
解决方法:针对网站建设,尽量避免采用这种策略,去吸引用户。
三:如何识别“蜘蛛陷阱”。对于识别蜘蛛陷阱的方法,特别容易,你只需要通过如下内容:
1、网站日志:利用工具读取当日蜘蛛抓取URL的内容,如果发现特殊的URL地址,那么值得进一步关注。
2、抓取频率:查看百度搜索资源平台中抓取频率,如果某一天数值特别大,那么很可能陷入蜘蛛陷阱。
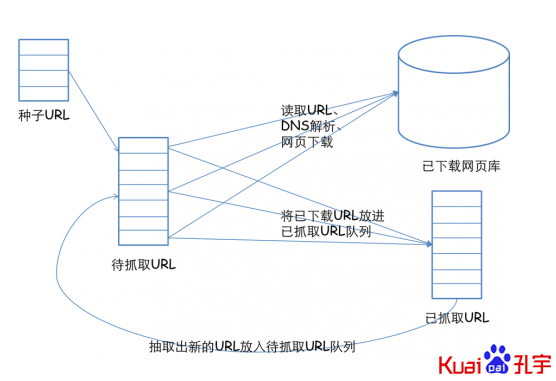
四、爬虫的基本原理,网络爬虫的基本工作流程如下:
1、首先选取一部分精心挑选的种子URL;
2、将这些URL放入待抓取URL队列;
3、从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
4、分析已抓取URL队列中的URL,分析页面里包含的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
五、爬虫爬取难点汇总:
1、环路:网络爬虫有时候会陷入循环或者环路中,比如从页面 A,A 链接到页面 B,B 链接 页面C,页面 C 又会链接到页面 A。这样就陷入到环路中。
环路造成的影响:
1.1、消耗网络带宽,无法获取其他页面
1.2、对 Web 服务器也是负担,可能击垮该站点,可能阻止正常用户访问该站点
1.3、即使没有性能影响,但获取大量重复页面也导致数据冗余
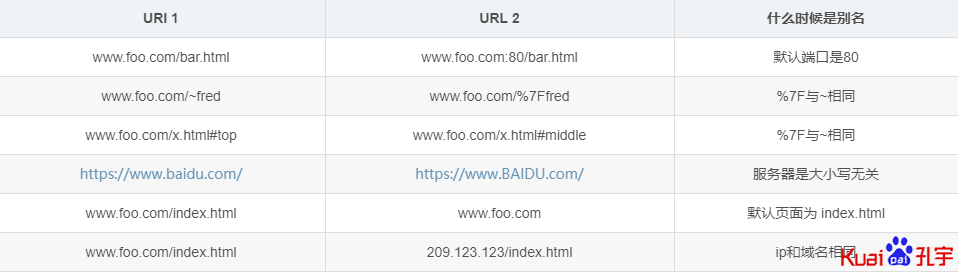
2、URL别名:有些 url 名称不一样,但是指向同一个资源。
3、动态虚拟空间:比如日历程序,它会生成一个指向下一月的链接,真正的用户是不会不停地请求下个月的链接的。但是不了解这内容特性的爬虫蜘蛛可能会不断向这些资源发出无穷的请求。


